Data Engineering: The Basis for Intelligent Document Processing

Published: January 23, 2026
A logistics company processed 50,000 shipping documents monthly using manual data entry. Staff spent 200 hours extracting addresses, weights, and tracking numbers from scanned forms. The company deployed an Intelligent Document Processing (IDP) workflow that automatically captured data from invoices and bills of lading. Data engineers have built validation rules to check address formats and flag suspicious weight entries before the information reaches the warehouse system. Processing time dropped to 20 hours per month, and delivery errors fell by 35%.
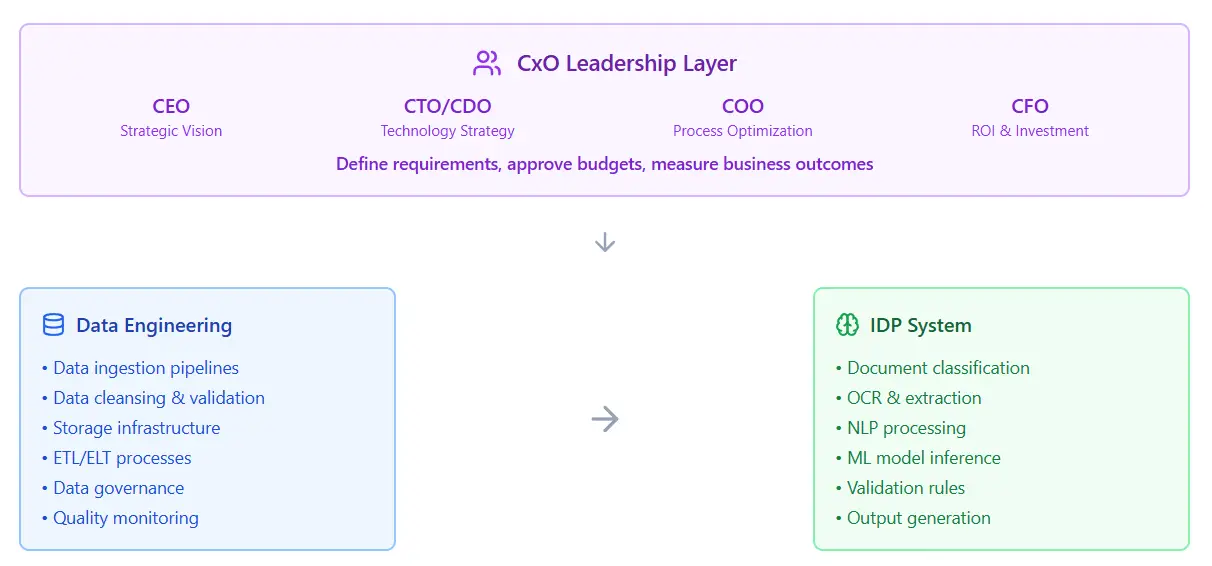
The relationship between data engineering, IDP, and CxO
Organizations deploy intelligent automation platforms to build the infrastructure, connectors, validation rules, workflows, monitoring dashboards, and exception handlers, that link disparate systems. These platforms function as the operational backbone for data movement and process orchestration. Data engineering strengthens this foundation by applying disciplined practices to data quality, transformation logic, and pipeline reliability. The value becomes clearer in complex ERP landscapes, where legacy systems and custom integrations involve exacting data management. Analytics initiatives also benefit: clean, well-structured data pipelines produce faster analysis and reduce the cost of fixing errors downstream.

docAlpha combines intelligent document processing with connectors, validation rules, monitoring, and exception handling, so extracted data is production-ready, not just readable. Turn AI extraction into reliable ERP-grade automation at scale.
Businesses process millions of documents each year, from invoices to contracts to medical forms. IDP promises to automate this work using AI that reads and extracts information without hands-on human presence.
IDP uses AI to extract and organize information from documents automatically. The technology reads invoices, contracts, forms, and receipts without human input. IDP systems come in three main types based on document structure:
Companies choose their IDP type based on document variety and processing volume.
Recommended reading: How AI Algorithms Transforming Intelligent Process Automation
IDP automates document handling across accounts payable, where it extracts provider invoices and payment terms.
Operationalize IDP At Enterprise Scale
docAlpha turns extraction into governed workflows with validation, exception handling, audit trails, and ERP-ready outputs. Reduce “AI-only” risk and make document automation reliable in production.
Book a demo now
IDP systems extract data and handle processing tasks on their own. They work out of the box and can route invoices, parse contracts, and populate fields without custom code. The output improves when engineers add validation rules, checks that catch dates in mixed formats or currency symbols that break accounting systems. Engineers also build pipelines that move extracted data into databases, ERPs, and analytics platforms, turning isolated outputs into connected workflows. Monitoring becomes sharper when teams track extraction trust levels, retrain models on new document types, and configure automated alerts for exceptions that would otherwise pile up silently.
A data engineering company builds the infrastructure that moves documents through ingestion, cleaning, extraction, validation, and loading into production systems. It’s a strategic solution for corporations intending to scale. Each stage requires custom logic, error handling, and monitoring to convert raw files into reliable business information.
It captures documents from multiple sources, email, scanners, cloud storage, or APIs, and routes them into a processing pipeline. The system validates file formats, applies optical character recognition to images, and extracts metadata before classification begins. It handles batches and real-time streams with equal competence. Built-in error handling catches corrupt files, missing pages, or unreadable text before they disrupt downstream workflows. The result is clean, structured data ready for analysis, storage, or connection to current business systems.
Recommended reading: How To Modernize Document Processing With Intelligent Process Automation
An IDP data preprocessing takes raw ingested documents and prepares them for intelligent analysis. The system removes noise like watermarks, stamps, and irrelevant headers that confuse extraction algorithms. It corrects image distortions, deskewing crooked scans, adjusting brightness, and sharpening blurred data to improve OCR accuracy. The solution normalizes document variations, converting different formats and layouts into consistent structures that downstream models can parse reliably. It identifies and flags incomplete documents, duplicate submissions, and pages with quality issues that need human review. Clean, standardized data exits the pipeline ready for classification, extraction, and business rule application.
Strengthen Ingestion and Preprocessing
docAlpha supports structured intake, OCR-ready preprocessing, and consistent data capture standards across multiple document sources. Increase accuracy and throughput without creating manual bottlenecks.
Book a demo now
The stage identifies and pulls specific information from documents, billing identifiers, dates, line items, addresses, and custom fields your business needs. ML models built with training on your document types recognize where data lives, even when layouts change between vendors or versions. The system handles structured forms, semi-structured invoices, and unstructured contracts with different techniques for each. Reliability indicators flag uncertain extractions for human review, so errors get caught before they enter your systems. Extracted data flows into databases, ERP platforms, or analytics tools in the format you specify.
Validation rules verify extracted information against business rules, databases, and external sources to catch errors before they cause problems. The system cross-checks invoice totals with line-item sums, verifies vendor numbers against your ERP master data, and flags dates that fall outside expected ranges. It applies custom logic specific to your workflows, purchase order matching, tax calculations, or regulatory compliance checks. Data that passes validation moves automatically into production systems, while exceptions are routed to specialists who can correct mistakes in seconds rather than days.
An IDP data loading takes validated information and writes it into your target systems, ERP platforms, document management systems, data warehouses, or custom applications. The system maps extracted fields to the correct database columns, API endpoints, or file formats that each destination requires. It handles errors smoothly: if a target system is unavailable or rejects a record, the solution queues the data and retries automatically. Audit trails capture every load operation with time stamps, user IDs, and success indicators for compliance reporting. Transaction management keeps related records together, so an invoice header never lands in your ERP absent its line items. The result is accurate data in the right place at the right time, ready for your teams to act on.
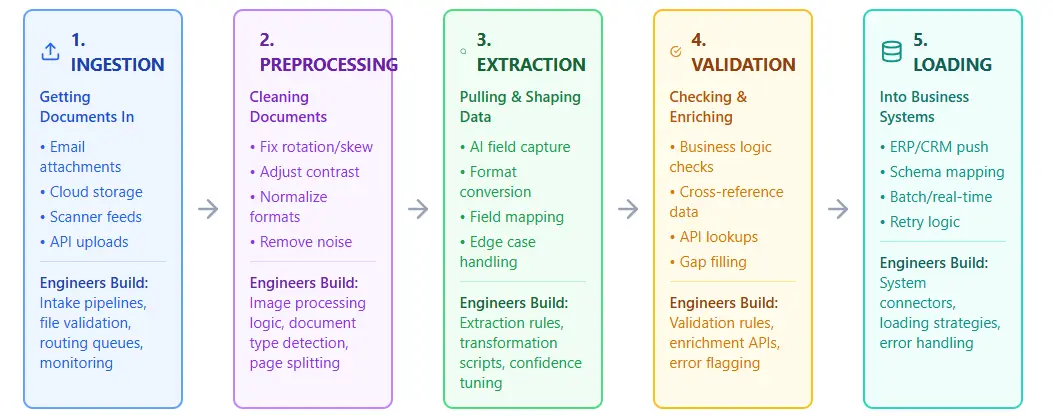
Critical stages where data engineers make IDP work
ETL extracts data from documents, transforms it into clean formats, and then loads it into target systems. The transformation happens before loading, so solely validated data enters the warehouse or ERP. ELT flips this order by loading raw extracted data first, then transforming it inside the target system. IDP workflows typically use ETL for structured documents where validation rules are clear and consistent. ELT suits situations where data scientists need access to raw extracted text for machine learning training or exploratory analysis.
Make ETL/ELT Outputs Business-Ready
docAlpha applies business rules, field validation, and confidence-based exception routing before data reaches ERP, finance, or compliance workflows. Prevent downstream rework and protect financial accuracy.
Book a demo now
Ingestion at scale: Modern ETL/ELT pipelines can automatically ingest thousands of PDFs, contracts, and invoices simultaneously.
Automated transformation: OCR + NLP extract structured fields (e.g., invoice codes, contract clauses) without physical handling.
Rapid loading: Data flows directly into ERP/CRM systems, reducing turnaround from days to minutes.
Impact: Faster compliance checks, quicker financial reconciliations, and minimized operational bottlenecks.
Standardization: ETL processes normalize diverse document formats into consistent schemas.
Validation rules: Built‑in checks verify that extracted data conforms to regulatory and accounting standards.
Audit trails: ELT pipelines preserve metadata and transformation logs for legal defensibility.
Impact: Reliable, compliant data accelerates audits, reporting, and contract lifecycle management.
Real‑time ELT: Pushes structured data directly into cloud warehouses or ERP/CRM systems.
Cross‑system linking: Financial and legal data can be enriched with master data (clients, vendors, case IDs).
Analytics ready: Immediate availability for dashboards, fraud detection, or risk scoring.
Impact: Organizations gain faster insights, supporting forward-thinking decision-making in finance and legal operations.
Recommended reading: Intelligent Automation: What Is It?
Data engineers design validation rules, build monitoring systems, and create feedback loops that catch extraction errors before they damage business operations. They implement automated checks at each pipeline stage, from ingestion through loading, and set confidence thresholds that route uncertain extractions to human reviewers.
IDP That Standardizes Every Invoice Format
InvoiceAction automates invoice processing by extracting fields reliably from PDFs, scans, and emails using intelligent rules. Increase straight-through processing and minimize exceptions.
Book a demo now
OCR technology scans document images and converts visible text into machine-readable characters. The software pinpoints letter shapes, word boundaries, and text blocks across the page. AI models go beyond basic character recognition via grasping document structure and context. Machine learning algorithms detect invoice headers, table rows, and signature blocks devoid of predefined templates. Natural language processing extracts meaning from unstructured text, identifying vendor names in paragraphs or dates buried in contract clauses. Computer vision models handle handwritten text, checkboxes, and stamped seals that traditional OCR misses. Together, OCR provides the raw text, and AI interprets what that content means for business processes.
OCR output contains recognition errors like "O" instead of "0" or "l" instead of "1" that break numeric fields. Engineers write regex patterns and lookup tables to catch common substitution mistakes and fix them automatically. Extra spaces, line breaks, and special characters get stripped from extracted data to match database field formats. Date parsers handle dozens of format variations, converting "12/05/24", "Dec 5, 2024", and "5-Dec-24" into a single standard. Currency symbols, thousands of separators, and decimal points need normalization before numeric calculations. Trust levels from AI models flag low-quality extractions that require human review or reprocessing. String matching algorithms compare extracted vendor names against master lists to correct typos and variations.
Poor data quality from IDP systems creates compounding problems across business operations. Incorrect invoice amounts trigger wrong payments, damaged vendor relationships, and audit failures. Bad data breaks downstream analytics, making reports unreliable for decision-making. Clean extraction calls for scrutiny of:
Data quality issues cost companies real money through manual corrections, payment errors, and compliance violations. Engineers build quality gates at each pipeline stage to catch problems early and sustain credibility in automated systems.
Protect Your Business From Extraction Errors
docAlpha combines intelligent extraction with quality gates, duplicate checks, and policy-driven validation to stop bad data at the source. Improve audit readiness and reduce costly manual corrections.
Book a demo now
Data engineering transforms chaotic document outputs into queryable structures. Raw text extraction from invoices or contracts creates messy data that analysts can't use. Engineers build the pipelines that standardize formats, validate fields, and link records across systems so ML models and dashboards actually work.
Most intelligent document processing platforms run on data lakes. The architecture handles unstructured content better than warehouses can. Documents arrive as PDFs, images, and scans. Data lakes store these raw files without forcing them into rigid tables first. Teams can extract text, train models, and build pipelines all in one place.
Turn Raw Documents Into Usable Data
docAlpha keeps documents and extracted data organized, validated, and searchable, so analytics and operations don’t depend on cleanup later. Accelerate insights without sacrificing data quality.
Book a demo now
IDP systems connect to cloud storage through native APIs. You point the platform at your S3 bucket, Google Cloud Storage container, or Azure Blob account. The system reads documents directly from these locations. Processed data writes back to the same storage or a different destination you specify. No file transfers or middleware required.
Data engineers enable analysts to run complex SQL queries across huge datasets.
Without solid engineering, analytics teams waste time fixing data problems instead of finding answers.
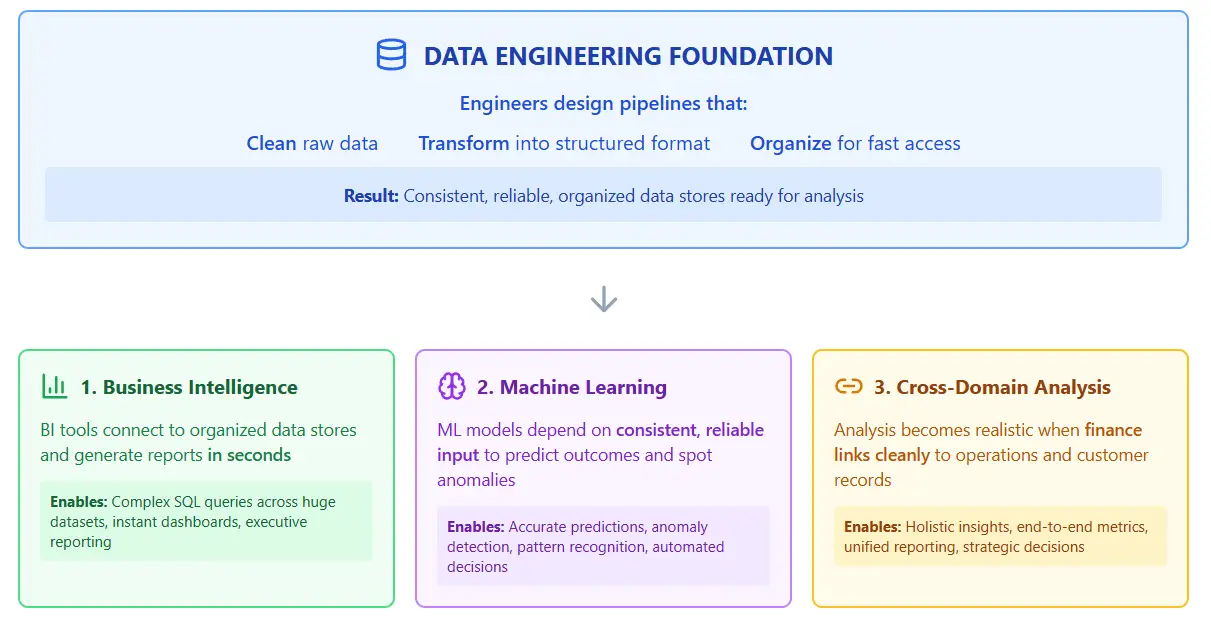
How data engineering acts as the basis for deep analytics
Each case demonstrates how proper data engineering creates the foundation for successful IDP implementation, resolving problems in data quality, standardization, and integration that would otherwise limit document processing effectiveness.
An insurance company deployed IDP to extract data from 50,000 claims documents monthly. The system pulled policy numbers, dates, and damage descriptions with 92% accuracy. Raw extractions contained inconsistent date formats, duplicate entries, and misaligned fields. Data engineers built validation pipelines that standardized formats and flagged anomalies. Claims analysts could then query the clean dataset to spot fraud patterns and calculate payout trends.
Recommended reading: What Is Intelligent Document Processing (IDP)
A law firm used IDP to process 10,000 vendor contracts for a merger review. The platform extracted clauses, renewal dates, and liability terms from each agreement. Extracted data arrived with spelling variations, missing values, and formatting errors from scanned documents. Engineers created transformation jobs that normalized company names, filled gaps with metadata, and linked related contracts. The team searched the structured database to identify risky clauses in minutes instead of weeks.
A hospital network implemented IDP to digitize paper records from three acquired clinics. The system scanned and extracted patient demographics, diagnoses, and medication lists. Output data mixed abbreviations, outdated codes, and conflicting information across sources. Data engineers mapped legacy codes to current standards, resolved patient duplicates, and built a unified health record database. Doctors could then access complete patient histories and predictive ML models to identify at-risk patients for intervention.
A regulatory agency needed to extract and analyze data from millions of business filings and compliance documents. Their data engineering solution included a distributed processing architecture, metadata management systems, and quality control workflows. This foundation enabled their IDP system to accurately identify and extract key regulatory information across multiple document types, minimizing processing backlogs by 87% and allowing the agency to focus resources on compliance review rather than manual data entry.
IDP Workflows That Move Invoices Automatically
InvoiceAction routes, approves, and posts invoices with automated business logic. Shorten cycle times and improve cash-flow predictability.
Book a demo now
Document processing is moving from simple text capture to self-governing decision-making. Future systems will combine generative intelligence with scalable data engineering to handle business logic at every stage.
Multimodal extraction: Modern models now read text and images together to understand document layouts. Engineers must build pipelines that feed both visual and semantic data into these systems.
Agentic workflows: AI agents now perform tasks like approving claims or routing files without human help. Data teams support this by building secure links between these agents and internal databases.
Generative understanding: Large language models can summarize complex contracts and answer questions about their contents. Engineering layers ensure these models have clean, applicable details to provide accurate answers.
Live processing: Business needs require documents to be processed the moment they arrive in the system. Engineers use event-driven tools to move data through the pipeline without any waiting time.
Self-correcting pipelines: Systems now use machine learning to find and fix errors in the data automatically. Data engineering provides the monitoring tools that track these changes and validate data quality.
Privacy-first design: New regulations require tight regulation of how personal data is treated in documents. Engineers build automated masking and encryption directly into the ingestion and storage layers.
Industry-focused models: Small, tailored models are replacing general AI, including legal or medical processing. Teams maintain the training data plus feedback cycles needed to keep these models sharp.
Recommended reading: Intelligent Automation in Data Entry: Humans vs Machine?
The CxO sets the budget for all data tools and staff. Leaders choose between on-the-fly processing and batch processing for the company. This choice determines the cloud systems for the engineering stack. A CTO picks the security rules for all document processing. Data teams build the protection layers to meet these rules. Decisions from the top office set the speed of the pipeline. Clear goals from a leader help engineers build only the most useful features.
 What Is Intelligent Document Processing (IDP)
What Is Intelligent Document Processing (IDP) How Data Analytics Drives Process Automation to Success
How Data Analytics Drives Process Automation to Success 7 Benefits of Document Processing Automation
7 Benefits of Document Processing Automation OCR: What Optical Character Recognition Is?
OCR: What Optical Character Recognition Is? Data Validation: Crucial for Invoice Processing Accuracy
Data Validation: Crucial for Invoice Processing Accuracy The Rise of Machine Learning in Business
The Rise of Machine Learning in Business
